
crazywall.png If you spent any time on tech LinkedIn in the spring of 2026, you probably saw them. They were everywhere. A highly coordinated swarm of 20-something engineers posting about a little-known Waterloo AI startup called Polarity. By the time the fellowship wrapped, Polarity had generated o...

I was talking to Mike Bird, who podcasts about AI tools. He asked me if I was using Hermes. "Of COURSE! Everyone knows HERMES. Who doesn't love a good... Hermes!" I said, slyly googling under the camera. Soon, I was having PTSD flashbacks to my experience with OpenClaw. Setting that up felt like get...
At first, you're excited. The easy stuff is easy, and it spurs you on. “I can do this.” You learn numbers. Common objects. Basketball for some reason. When you say something to a native speaker, their face lights up. “Lihai! Your Chinese is so good!” They don’t point out that you accidentally said,...

Waterloo birthed BlackBerry, Faire, and Tailscale. If you are in town hunting for the next billion-dollar startup, do not waste your time taking meetings in generic hotel lobbies. I tracked the top funding rounds out of Waterloo this year, and a massive percentage of them were quietly brokered over...
Last night, I was rejected from yet another pitch night. It was just the pre-interview, and the problem wasn't my product. I already have MRR. I already have users who depend on it every day. The feedback was simply: "What do you even need funding for?" I hear this time and time again when I try to...

I was working on a project the other night, using Google's Gemini to help brainstorm a technical plan. If you've used it recently, you've probably seen the "Canvas" feature. It pops up on the right side of your screen, rendering code and text beautifully. It looks great. But then I actually finished...

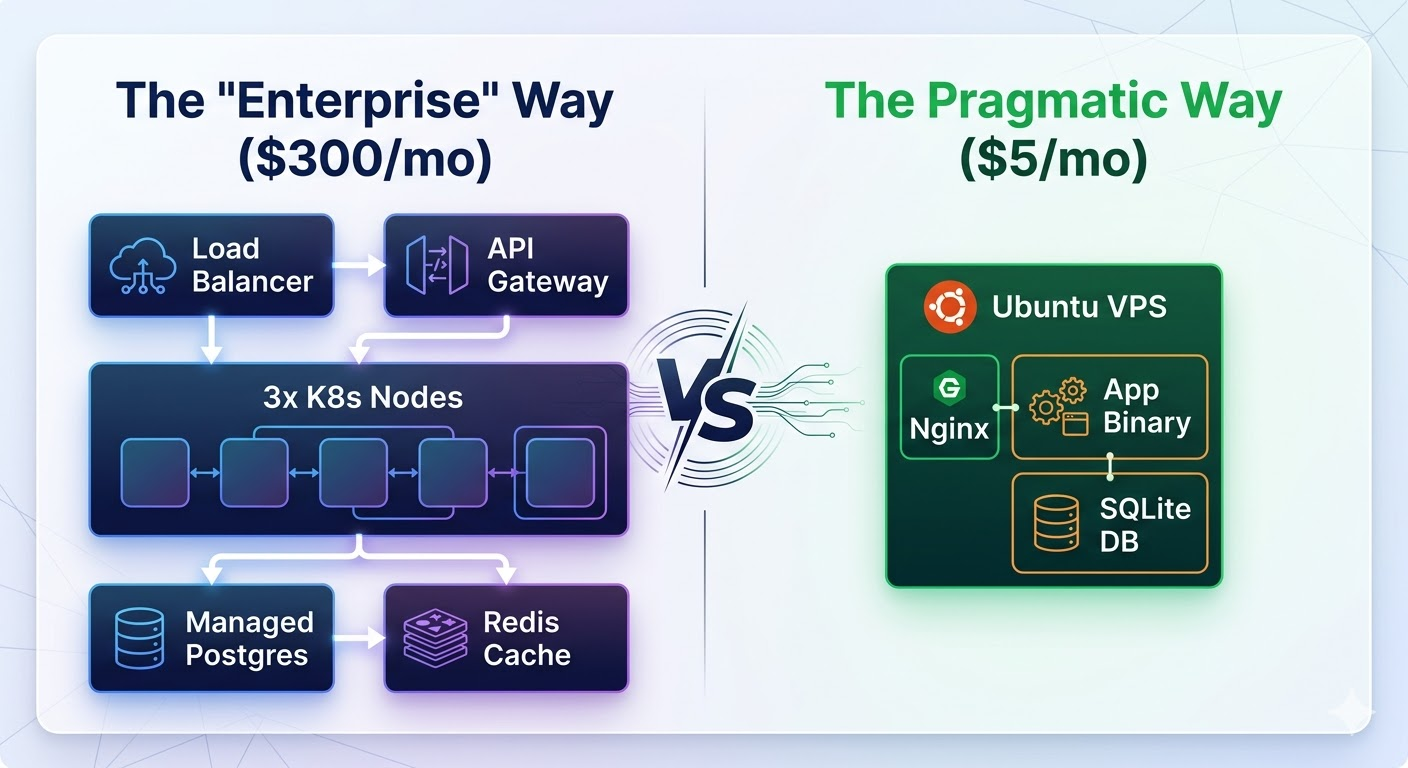
I recently had a problem that could be solved with money, which is the worst kind of problem. I am building a new venture called eh-trade.ca. To make it work, I needed deep financial research on 11,000 different stocks. The "Enterprise" solution is to buy an API subscription. I looked into this. For...
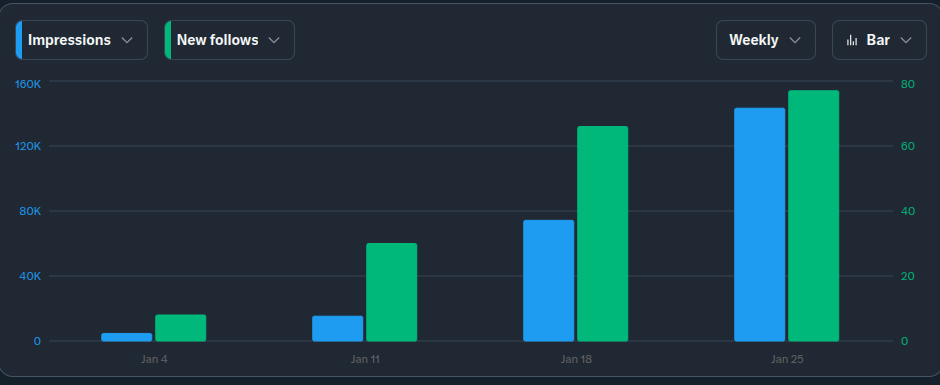
My X (formerly Twitter) account is 17 years old. In internet years, that’s ancient . For a long time, that history was a badge of honor. But recently, when I tried to pivot my focus from general tech to financials and SaaS growth, I realized that my history was actually an anchor. The algorithm had...

I'll admit it. I've been neglecting my blog. I went back recently and found a wall of comment spam. I've tried various ways of fighting it over the years. For a while, having written my own blog in php meant the problem wouldn't exist. The bots would relentlessly try submitting comments via wordpres...
I'll take you step by step into how to make a service that takes screenshots of webpages and returns them as an image. First, let's assume you have google-chrome or chromium-browser installed. Both should work the same way. These browsers have command line options that let you capture a screenshot i...

New, 2024! Updated with AI Originally mosted March 4, 2009. Though I must say, my comments section has gotten out of hand. I recently started re-reading William Zinsser's On Writing Well. Zinsser emphasizes simplicity in writing. To reduce wordiness, he implores the writer to remove needless words a...
I found Security Vulnerability in your web application. For security purpose can we report vulnerability here,then will i get bounty reward in PayPal or Bitcoin for Security bug ? Is it just me, or are security consultants swarming web sites, looking for bugs unasked, and emailing you demanding thou...
If you are writing an application in Javascript, soon you will have to worry about memory leaks. But it is difficult to even know if a memory leak exists. This handy method can help. WeakMap At first, you may think that WeakMap will do it. WeakMap/WeakSet will hold onto things for you, but don't pre...

I have never been a gamer. The most I've played was Super Mario Bros (the original). I then took a break for a decade or so and spent a few weeks with Simcity 4. Something happened last week. Overnight, I've become addicted to games. The cause was this: It arrived the next day after I ordered it fro...
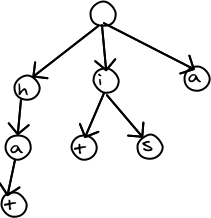
ABSTRACT The difference between two sequences A and B can be compactly stored using COPY/INSERT operations. The greedy algorithm for finding these operations relies on an efficient way of finding the longest matching part of A of any given position in B. This article describes how to use a suffix ar...

So I have two million song lyrics in a big file. Don't ask me how I got it. The point is that I want to find the most poetic phrase of all time. Problem is, the origins of this file are so sketchy it would make a Pearls Before Swine cartoon look like a Da Vinci. There could well be thousands of copi...
Drag a font file here to reveal its innermost secrets! Here's one in case you don't have one handy. Drag TTF file here Source code Here are the steps we will follow: When the file is dragged onto the web page, we want to read it. We need to be able to interpret the numbers in the file, even though t...
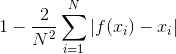
How do you measure the "sortedness" of a list? There are several ways. In the literature this measure is called the "distance to monotonicity" or the "measure of disorder" depending on who you read. It is still an active area of research when items are presented to the algorithm one at a time. In th...

I hate all the languages. Once, I tried to make my own language, but I couldn't figure out what language to do it in, so I never started. Most of the time, you don't have any choice of what language to work in. Whatever language I'm using, I've learned to appreciate both its strengths and weaknesses...

In late 2011, we were crammed in the table in the break room. "I tried to book the meeting room but it's booked all week for the layoffs," said James. Times were bleak at BlackBerry. Last Friday 11% of the workforce, over two thousand people, were laid off. On that day I had passed a red faced man b...
I couldn't sleep. Took some neo citron for my cold and rewrote the rhymebrain instant algorithm. When you start typing "ox" into rhymebrain, there is almost 100% chance that you are going to type "oxygen". Likewise for "or" it is "orange". There is a perceived time savings if rhymebrain prefetches t...

Warning For qualified advice, ask an organization such as the chamber of commerce. Here is some information from BDO for Canadians on selling to the USA. If you can pay for advice, you should set up an appointment with an adviser. After many months, your software sale is complete! You've got a purch...
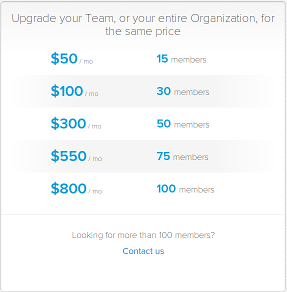
If one apple costs $1, how much would five apples cost? How about 500? In everyday life, when you buy more of something, you get more bananas for your buck. The fixed costs decrease. If you sell a lot of apples to one person, you don't have to wrap each one, you don't have to pay fixed transaction f...

Powtoon is online software that lets you create animated powerpoint presentations, without the steep learning curve of Adobe Flash. The selling techniques they use are simple and powerful. Even though I saw through their tricks at every step along the way, I am now a customer and proud of it. It is...

I first realized I had overpaid when I received my articles of incorporation from the law firm. Was it because they were in a leather bound binder? Was it because it had been shipped overnight from Toronto to Waterloo, a distance of 83 km, such a distance that I could have driven there and picked it...

There are only four numbers in computer programs: 0, 1, many, "a zillion" If you have 2 or more of anything, you are, in general, better off using loops to process many of them. But what is "a zillion?" Zillion is a made-up number. Your system cannot hold a zillion items in memory. It cannot show a...

This August marks the 30th anniversary of the most successful computer model in history. One company put personal computers into the people's homes, and launched an entire industry overnight. For an entire decade, despite attempts at marketing improvements, the original platform stood the test of ti...

Zwibbler.com is a drop-in solution that lets users draw on your web site. A/B testing is used far too often, for something that performs so badly. It is defective by design: Segment users into two groups. Show the A group the old, tried and true stuff. Show the B group the new whiz-bang design with...
![[comic] Appreciation of xkcd comics vs. technical ability](http://zwibbler.com/shared/897.png)
Previous Comic Next Comic
Let's say you have millions of pictures of faces tagged with names. Given a new photo, how do you find the name of person that the photo most resembles? Suppose you have scanned short sections of millions of songs, and for each five second period you have a rough list of the frequencies and beat pat...

Most people, having already paid $2000.00 of their hard earned money, and then having flown, driven, or otherwise travelled to Boston to attend a conference, and then having paid an additional $250/night plus $33/night parking and "tourism taxes" to the Seaport Hotel -- most people, after all this,...
Javascript was not designed to do asynchronous operations easily. If it were, then writing asynchronous code would be as easy as writing blocking code. Instead, developers in node.js need to manage many levels of callbacks. Today, we will examine four different methods of performing the same task as...
Sometimes you cannot afford to load data files from disk. Maybe you need results immediately, or the data is simply too large to fit into memory. A technique that I like to use is an on-disk data structure. Here is a toy example for instantly accessing lists of related words. In this article, I addr...
Algorithms will always matter. Sure, processor speeds are still increasing. But the problems that we want to solve using those processors are increasing in size faster. People who are dealing with social network graphs, or analyzing twitter posts, or searching images, or solving any of the hundreds...
Many good web applications, and many bad ones, have an API, and my hobby project, RhymeBrain.com, is no exception. The trouble is: the target users of both the web site and the API don't know the difference between Javascript and Java. They don't even know what "A.P.I." stands for. The most they can...
Let's continue our short tour of data structures for storing words. Today, we will over-optimize John Resig's Word Game. Along the way, we shall learn about a little-known branch of computer science, called succinct data structures . John wants to load a large dictionary of words into a web applicat...
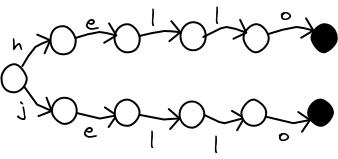
CORRECTION : In this article, I incorrectly state that an acyclic finite state automata (aka a DAWG) cannot be used to retrieve values associated with its keys. I have since learned that it can. By storing in each internal node the number of leaf nodes that are reachable from it, we can, upon arrivi...

In the 80's, computers started instantly. They were READY to go when they first turned on. Over the next few decades, people wanted to do more things and operating systems got slower to initialize. To solve this, OS and hardware manufacturers created hibernate and standby modes. Now, many people hav...
Are you looking for a nifty way to choose colours that stand out? Are you the type of person who is not satisfied until you have mathematically proven that your choice is optimal? One way to do it is to treat red, green, and blue colour values as coordinates in a cube. Two colours are different if t...
Last time, I wrote about how to speed up spell checking using a trie (also known as a prefix tree). However, for large dictionaries, a trie can waste a lot of memory. If you're trying to squeeze an application into a mobile device, every kilobyte counts. Consider this trie, with two words in it. It...
If you have a web site with a search function, you will rapidly realize that most mortals are terrible typists. Many searches contain mispelled words, and users will expect these searches to magically work. This magic is often done using levenshtein distance. In this article, I'll compare two ways o...
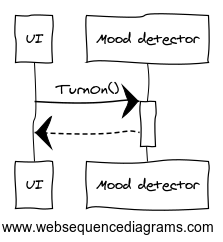
The imaginary Larmin Corp is designing the next killer product: A mood ring. Okay it's too big to wear around your finger and is more of a wrist device. But it works with 80% accuracy and it's got its own app store and it is expected to be a big hit at CES. There's a snag: unnamed sources are attrib...
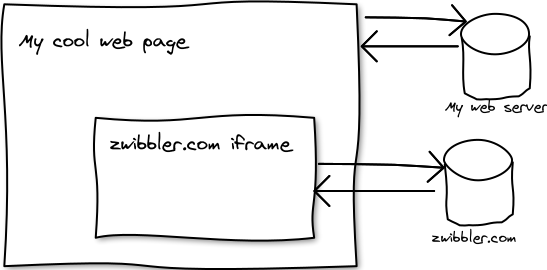
Making a web application mashable -- useable in another web page -- has some challenges in the area of cross-domain communications. Here is how I solved those problems for Zwibbler.com. (See the API demo here) Zwibbler consists of a large javascript program and a little HTML. The javascript part use...
There are at least two kinds of programming interviews. One type is where you are asked for details about your prior work experience. The other one is where they put you in a room, give you a problem, and stare at you while you fumble around with markers on a whiteboard for 45 minutes. The first foc...

In a job interview, I once asked a very experienced embedded software developer to write a program that reverses a string and prints it on the screen. He struggled with this basic task. This man was awesome. Give him a bucket of spare parts, and he could build a robot and program it to navigate arou...

JSON is horribly inefficient data format for data exchange between a web server and a browser. For one, it converts everything to text. The value 3.141592653589793 takes only 8 bytes of memory, but JSON.stringify() expands it to 17. A second problem is its excessive use of quotes, which add two byte...

The HSV colour wheel, based on barycentric coordinates, is my favourite colour selection device. It discourages picking unnatural looking saturated colours. Instead, it gives the realistic designer colours more space in the triangle. That's why I chose it for Zwibbler.com, my online Javascript sketc...
At some point in your programming career you may have to go through a graph of items and process them all exactly once. If you keep following neighbours, the path might loop back on itself, so you need to keep track of which ones have been processed already. The code works, but it only works once! T...
A common misconception about software development: When a bug occurs, users will it into a tracking system with detailed information on how to reproduce it. A developer walks through the given steps to reproduce the issue, finds the problem, and submits a fix That's based on several bad assumptions....
Distributing applications on Linux is hard. Sure, with modern package management, installing software is easy. But if you are distributing an application, you probably need one Windows version, plus umpteen different versions for Linux. In this article, we'll create a dummy application that targets...

This post also appears, with my permission, on A Smart Bear, with additional editorial comments by Jason Cohen, founder of Smart Bear Software. For a micro-ISV, selling to businesses can be more lucrative than selling to consumers. Instead of making a few dollars per sale and hoping for thousands of...
If you open the first few pages of O'Reilly's Beautiful Code, you will find a well written chapter by Brian Kernighan (Personal motto: "No, I didn't invent C. Who told you that?"). The non-C inventing professor describes how a limited form of regular expressions can be implemented elegantly in only...

On Monday, I was pleased to be an uninvited speaker at Waterloo Devhouse, hosted in Postrank's magnificent office. After making some surreptitious alterations to their agile development wall, I gave a tongue-in-cheek talk on how C++ can fit in to a web application. There were other cool presentation...

If your browser supports the proposed CANVAS tag, you will see a screen below containing a BASIC program. This only implements enough of the language to run NIBBLES.BAS Many programmers seldom think about how their compiler or scripting language is implemented. To them, it is a tool, and the less it...

Tested under Firefox 3.5.6 and Google Chrome 3.0.195.38 Introduction This project extends the technique I created for imprecise line-drawing to create an entire vector graphics application, similar to Inkscape. It is written almost entirely in Javascript, except for a server-side program that render...

You learn a lot of things on the job as a programmer. Years ago, at my first coop position, I was a little confused when my boss went to Visual C++, and tried to open the .EXE file as a project. What a dolt! I thought. That's not going to work. Luckily I kept my mouth shut. You don't need to create...

Previous Comic Next Comic STARTUP INK It's a re-run, from before I used computerized lettering.

Previous Comic Next Comic STARTUP INK
The <canvas> tag is the current fangled way of displaying vector graphics in a web browser. Before, all graphics were images, Flash animations, or even thousands of one-pixel <div>s. Finally, Internet browsers have caught up to the 1970s and will be able to draw lines and curves programm...

Previous Comic Next Comic STARTUP INK

Previous Comic Next Comic STARTUP INK

Previous Comic Next Comic STARTUP INK
"expertsexchange.com" is a domain name that can be read in multiple, unintended ways. Howshouldatexttospeechsystemresolvethisambiguity? Recently, I was contracted to run a list of domain names through the custom-built pronunciation engine that powers my rhyming web site. On the first attempt, I foun...

Previous Comic Next Comic STARTUP INK

Back in 2007, I created a rhyming engine based on the public domain Moby pronouncing dictionary. It simply reads the dictionary and looks for rhyming words by comparing the suffix of the words' pronunciations. Since that time, I have made some improvements. rhyme any word Using a comnbiation of tech...

Previous Comic Next Comic STARTUP INK
For years when running this blog, I would have to log in each day and delete a dozen comments due to spam. This was a chore, and I tried many ways to stem the tide. Finally, a few months ago, I found a way that worked 100% of the time. This raw text file shows what I'm up against, containing all ser...

Previous Comic Next Comic STARTUP INK May contain characters from xkcd, used under license. However, for this work, all rights are reserved. Coyright © 2009 Steve Hanov

Back in high school, I had too much free time, so I decided to play a joke on my computer teacher. I created an exact clone of the school's DOS system using QBasic. It would pretend to execute three commands: DIR, DEL \ .\ , and FORMAT. The simulation was so realistic that during development, I was...

Previous Comic Next Comic STARTUP INK

There are plenty of places you can go if you just want to put up some static web pages for free, or very low cost. But costs go up very quickly if you need to do any more than that, or if you get spikes in traffic. Sometimes you need complete control over the server, and don't want to pay $20 to $40...

Previous Comic Next Comic STARTUP INK
My web site has been going up and down over the night. I've intentionally been trying to elicit reddit traffic so I can test different parameters for apache server optimization, to handle high traffic over slow connections. A netbook can be ideal for a home web server. They are cheap, and use less p...

Previous Comic Next Comic STARTUP INK

Previous Comic Next Comic STARTUP INK "I just don't have any ideas." This is the #1 stumbling block for budding entrepreneurs. Here are a few techniques to get the creative juices flowing. Copy somebody else, but fix the problems If you have a lack of ideas, you might be mentally discarding lots of...

Disclaimer : Use these tips at your own risk. Don't get career advice from bloggers. When you get a new job, you can breathe a sigh of relief, but not for long. You have an offer letter in your hand, and it is easy to miss one of the most important opportunities of your life: the starting salary. He...

Here are some C coding tips, because I have been unable to post anything for a while. Some of these time-saving shortcuts are intended for small projects or prototyping code. The nested ? : trick The switch statement is very efficient, and the compiler will often implement it as a table lookup so it...
If a reporter asks you about your new startup company, be careful what you say. The statement that sounds best will be quoted. Some of what you say will be re-ordered or deleted. Long, rambling descriptions will be paraphrased and condensed. Here is a pitch from a new startup company, taken from an...
Every company that I worked for has its own method of testing, and I've gained a lot of experience in what works and what doesn't. At last, that stack of conflicting confidentiality agreements that I got as a coop student have now all expired, so I can talk about it. (I never signed them anyway.) Wa...
I use graphviz whenever I need to draw state machine diagrams. Drawing circles connected with lines is a hard problem for computers, because they have to decide where to place the circles so the diagram makes sense. These types of diagrams are called graphs. To my surprise, I found that there is a v...

Burgeoning numbers of Ph.D's and grad students are choosing to study pornography. Techniques for the analysis of "objectionable images" are gaining increased attention (and grant money) from governments and research institutions around the world, as well as Google. But what, exactly, does computer s...

I once took computer vision class. Every algorithm we learned was done on grayscale images, as if it were 1950 and we couldn't afford those new fangled colour VDTs. I put up my hand and asked why we discard all of this lovely colour information. The prof answered that some people have tried it, but...

Once you post something on the Internet, it is hard to get rid of it. As an experiment, I deleted one of my past posts, and I tried to remove all traces of it. I selected my post about Technical Interview tips, because it is mildly popular, but never did very well. It was on reddit for only a couple...

It is common knowledge that Linux users needn't worry about viruses because users don't run as root. I've never understood the reasoning behind this. Here are a few of the malicious things that a program can do without being root on Ubuntu 8.10: Start a program every time you login Configure firefox...
If you begin your emails with "Hi, <name>!" then they will seem less rude. Compare to: See what I mean?

Previous Comic Next Comic Click to enlarge Japanese Translation by Yasushi Aoki Unauthorized Chinese translation, I think. Here are the real tips How to recognize a good programmer Another Resume Tip - From Joel on Software Ten Tips for a Slightly Less Awful Resume - Advice from Steve Yegge. An ente...

Based on 22500 unique IP addresses over the past week, reddit users have these browser widths: The numbers on the bottom are browser widths (minus 40), and the numbers on the side are the counts of unique visitors with that width. Data collection At the time this blog posting was made, my blog had h...

Quick! Where do you go to increase the text size in all your applications? Can you pick the right button on the first try? Do you feel lucky, punk? I might try: Desktop , because it's at the top, I see it first, and text is a part of my desktop experience. Display , because that's where the setting...

This really should have been included in cairo. Instead, everyone that wants to have shadows has to roll their own blur function. Here's my take on it. I'll even release this into the public domain. This is used in the back-end for www.websequencediagrams.com.
Okay, say you work at a company that uses Perforce (on Windows). So you're happily tapping away using perforce for years and years. Perforce is pretty fast -- I mean, it has this "nocompress" option that you can tweak and turn on and off depending on where you are, and it generally lets you get your...
If you've installed Ubuntu on a USB key or SD card, you are probably experiencing the annoying slowness of Firefox. It freezes up for a couple of seconds every time you click a link. Like many things on Ubuntu, it doesn't work right out of the box and needs some tweaking. Fortunately, by following t...
Geez, I just went through my server logs and it is clear that people have lots of questions on UMA. Whenever someone asks a question in Google, and my web page pops up, and they click on it, I can see what they typed into Google. So in a way, all of you people on the Internet are able to tell me wha...

To further my understanding of frequency analysis and the fast fourier transform, I have created an application that just turns on the microphone and continually plots the FFT magnitude of what it records. It allows control over the window size and sampling rate. Download SoundLab Because the FFT of...
The stock market is a lot different than it was just a few months ago. Once again, I present my stock selections, as found via python script. Comparing it with last time, you will find most of the same names are on there. Financial data for 1600 public companies listed on the TSX is downloaded from...
I stumbled accross this page about myself on this rotten company Spoke.com, who, without my permission, gathered my name and employment history together into one place. I object to it, but there was no obvious way to get it removed. After a lot of searching, I found a contact page and filled it out,...

I just spent several hours debugging clipboard copy of a DIB image. I could copy from my application, and paste into Paint. I could paste into Word. But if I pasted into WordPad, nothing showed up. If I pasted into GIMP, it crashed. The general procedure is to fill out a BITMAPINFO structure, calcul...

Have a look at this image. You might think I scrawled it on a napkin and scanned it in. Wrong! It was completely automatically generated by an upcoming release of www.websequencediagrams.com, with the new "napkin" style. Getting it to render this way was easy, simply with a tiny bit of math and a ch...
Why can't anybody write a decent stock screener? Google did, but they left out my favourite exchange, the TSX. The best indicator of whether a stock is going to go up in the medium term is growth in earnings, but it is near impossible to find this information for Canadian stocks. I have tried the on...

Cairo is the hot new cross platform graphics library. It is becoming very popular, because it solves two outstanding problems in a portable way: Path based drawing Antialiasing Both of these problems are astoundingly hard. You would have to read a whole graphics textbook in order to implement basic...
How many times have you needed to calculate something, for example the value of 0x398A3BB, so you pop up windows calculator to convert it? I did lots of times. The problem is I hate to use the mouse. It takes precious deciseconds away from software development time to remove my hands from the keyboa...

If you have to draw something called "UML Sequence Diagrams" for work or school, you already know that it can take hours to get a diagram to look right. Here's a web site that will save you some time: www.websequencediagams.com You can just write the diagram out in text, click "Draw", and the web si...

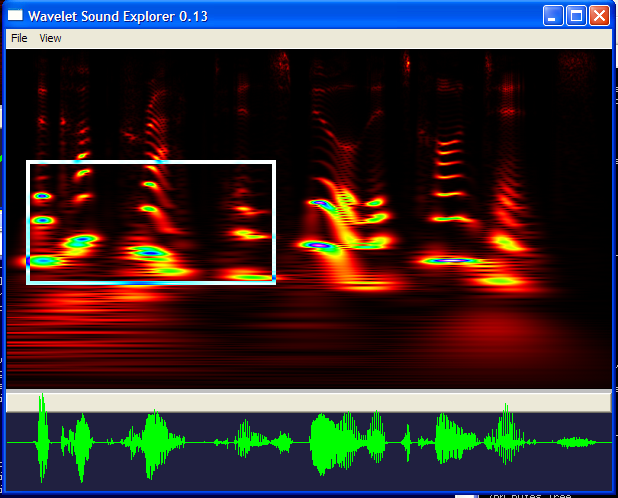
Here's a program to create scalograms of sound files. Pictured below is the "windows xp startup sound". See how the individual frequencies have been isolated visually. I have created a separate web page for this project... please go there. Download Installer I've been curious about wavelets since I...
UMA and free long distance Last time, I talked about the UMA technology used in some newer cell phones. Some of you might be thinking, these new cell phones work over the Internet. What's to stop me from travelling to another continent, and then making free long distance calls to local numbers back...
For more UMA answers, see my more recent article. What's UMA? Recently, many carriers have started offering UMA, or WiFi phones. These are cell phones with WiFi capabilites. Don't be fooled -- you won't be able to get free calls and run skype on them. The UMA technology is meant to extend the carrie...

The challenge: Install Linux on a really old laptop. The catch: It has only 32 MB of RAM, no network ports, no CD-ROM , and the floppy drive makes creaking noises. Is it possible? Yes. Is it easy? No. Is is useful? Maybe... Motivation Why? Like mountain climbers say: because it's there. As an enviro...
Is it possible to make money on the internet, if you try really hard? I want to find out. I have always been interested in getting money for doing nothing. In an ideal business, you would do some initial work to get a system set up, and then wait for cash to come in. Here are some results, including...

A while back I thought it would be interesting to be able to draw arbitrary waveforms and then listen to how they sound. I had an audio engine just laying around, so I whipped up a quick application to do that. download WaveStudio.exe Results In theory, you can make any sound that you want. The resu...
Much ink has been spilled about the use of cell phones on airplanes. Here's the truth, which will be disappointing to conspiracy theorists: Cell phone signals most definately have an effect on other electronic equipment. Read on for more. Want proof? hold you cell phone near your computer speakers....
A while ago I had the problem of detecting memory leaks in my code, and I didn't want to spend lots of money on a brittle software package to do that. It's fairly simple to redefine malloc() and free() to your own functions, to track the file and line number of memory leaks. But what about the new()...
Type it in here and see. You might want to visit DialAbc.com, which has more results. Stay here if you are interested in the theory behind it. This article was actually written in 2002. Here, I explain a technique for figuring out which words are in which phone numbers. Full C source code is include...
Here's a rhyming engine, written in 1000 lines of C++ code. It uses the freely available Moby dictionary, and full source code is provided. Give it a try. Read on for technical information. Please try the updated rhyming web site. Results: ## Relationship to Rhymebrain.com I originally wrote this po...
I used to be a strong supporter of C++. It was the perfect language. In C++, if you want to influence how the hardware instructions are generated, you can do that. If you want to program without pointers and without caring about how memory is allocated, you can do that. Recently, however, my views h...
I am a mobile telecommunications "engineer", and I thought I'd explain what to look for in a cell phone. Most guides will review phones on their user interface, but pay little attention to one of the most important pieces: the radio. The radio on GSM cell phones is very mysterious to most people, so...
