
Throw away the keys: Easy, Minimal Perfect Hashing
Posted 14 years ago
CORRECTION: In this article, I incorrectly state that an acyclic finite state automata (aka a DAWG) cannot be used to retrieve values associated with its keys. I have since learned that it can. By storing in each internal node the number of leaf nodes that are reachable from it, we can, upon arriving at the destination key, know its unique index number. Then its value can be looked up in an array. I am now using this technique on rhymebrain.com
This technique is described in Kowaltowski, T.; CL. Lucchesi (1993), "Applications of finite automata representing large vocabularies", Software-Practice and Experience 1993
Here's my implementation using an MA-FSA as a map: Github
In part 1 of this series, I described how to find the closest match in a dictionary of words using a Trie. Such searches are useful because users often mistype queries. But tries can take a lot of memory -- so much that they may not even fit in the 2 to 4 GB limit imposed by 32-bit operating systems.
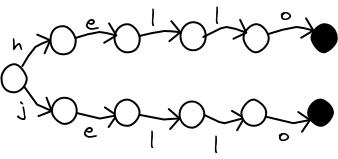
In part 2, I described how to build a MA-FSA (also known as a DAWG). The MA-FSA greatly reduces the number of nodes needed to store the same information as a trie. They are quick to build, and you can safely substitute an MA-FSA for a trie in the fuzzy search algorithm.
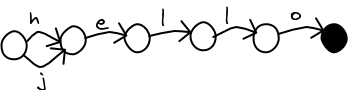
There is a problem. Since the last node in a word is shared with other words, it is not possible to store data in it. We can use the MA-FSA to check if a word (or a close match) is in the dictionary, but we cannot look up any other information about the word!
If we need extra information about the words, we can use an additional data structure along with the MA-FSA. We can store it in a hash table. Here's an example of a hash table that uses separate chaining. To look up a word, we run it through a hash function, H() which returns a number. We then look at all the items in that "bucket" to find the data. Since there should be only a small number of words in each bucket, the search is very fast.

Notice that the table needs to store the keys (the words that we want to look up) as well as the data associated with them. It needs them to resolve collisions -- when two words hash to the same bucket. Sometimes these keys take up too much storage space. For example, you might be storing information about all of the URLs on the entire Internet, or parts of the human genome. In our case, we already store the words in the MA-FSA, and it is redundant to duplicate them in the hash table as well. If we could guarantee that there were no collisions, we could throw away the keys of the hash table.
Minimal perfect hashing
Perfect hashing is a technique for building a hash table with no collisions. It is only possible to build one when we know all of the keys in advance. Minimal perfect hashing implies that the resulting table contains one entry for each key, and no empty slots.
We use two levels of hash functions. The first one, H(key), gets a position in an intermediate array, G. The second function, F(d, key), uses the extra information from G to find the unique position for the key. The scheme will always returns a value, so it works as long as we know for sure that what we are searching for is in the table. Otherwise, it will return bad information. Fortunately, our MA-FSA can tell us whether a value is in the table. If we did not have this information, then we could also store the keys with the values in the value table.
In the example below, the words "blue" and "cat" both hash to the same position using the H() function. However, the second level hash, F, combined with the d-value, puts them into different slots.

In step 1, we place the keys into buckets according to the first hash function, H.
In step 2, we process the buckets largest first and try to place all the keys it contains in an empty slot of the value table using F(d=1, key). If that is unsuccessful, we keep trying with successively larger values of d. It sounds like it would take a long time, but in reality it doesn't. Since we try to find the d value for the buckets with the most items early, they are likely to find empty spots. When we get to buckets with just one item, we can simply place them into the next unoccopied spot.
Here's some python code to demonstrate the technique. In it, we use H = F(0, key) to simplify things.
#!/usr/bin/python
# Easy Perfect Minimal Hashing
# By Steve Hanov. Released to the public domain.
#
# Based on:
# Edward A. Fox, Lenwood S. Heath, Qi Fan Chen and Amjad M. Daoud,
# "Practical minimal perfect hash functions for large databases", CACM, 35(1):105-121
# also a good reference:
# Compress, Hash, and Displace algorithm by Djamal Belazzougui,
# Fabiano C. Botelho, and Martin Dietzfelbinger
import sys
DICTIONARY = "/usr/share/dict/words"
TEST_WORDS = sys.argv[1:]
if len(TEST_WORDS) == 0:
TEST_WORDS = ['hello', 'goodbye', 'dog', 'cat']
# Calculates a distinct hash function for a given string. Each value of the
# integer d results in a different hash value.
def hash( d, str ):
if d == 0: d = 0x01000193
# Use the FNV algorithm from http://isthe.com/chongo/tech/comp/fnv/
for c in str:
d = ( (d * 0x01000193) ^ ord(c) ) & 0xffffffff;
return d
# Computes a minimal perfect hash table using the given python dictionary. It
# returns a tuple (G, V). G and V are both arrays. G contains the intermediate
# table of values needed to compute the index of the value in V. V contains the
# values of the dictionary.
def CreateMinimalPerfectHash( dict ):
size = len(dict)
# Step 1: Place all of the keys into buckets
buckets = [ [] for i in range(size) ]
G = [0] * size
values = [None] * size
for key in dict.keys():
buckets[hash(0, key) % size].append( key )
# Step 2: Sort the buckets and process the ones with the most items first.
buckets.sort( key=len, reverse=True )
for b in xrange( size ):
bucket = buckets[b]
if len(bucket) <= 1: break
d = 1
item = 0
slots = []
# Repeatedly try different values of d until we find a hash function
# that places all items in the bucket into free slots
while item < len(bucket):
slot = hash( d, bucket[item] ) % size
if values[slot] != None or slot in slots:
d += 1
item = 0
slots = []
else:
slots.append( slot )
item += 1
G[hash(0, bucket[0]) % size] = d
for i in range(len(bucket)):
values[slots[i]] = dict[bucket[i]]
if ( b % 1000 ) == 0:
print "bucket %d r" % (b),
sys.stdout.flush()
# Only buckets with 1 item remain. Process them more quickly by directly
# placing them into a free slot. Use a negative value of d to indicate
# this.
freelist = []
for i in xrange(size):
if values[i] == None: freelist.append( i )
for b in xrange( b, size ):
bucket = buckets[b]
if len(bucket) == 0: break
slot = freelist.pop()
# We subtract one to ensure it's negative even if the zeroeth slot was
# used.
G[hash(0, bucket[0]) % size] = -slot-1
values[slot] = dict[bucket[0]]
if ( b % 1000 ) == 0:
print "bucket %d r" % (b),
sys.stdout.flush()
return (G, values)
# Look up a value in the hash table, defined by G and V.
def PerfectHashLookup( G, V, key ):
d = G[hash(0,key) % len(G)]
if d < 0: return V[-d-1]
return V[hash(d, key) % len(V)]
print "Reading words"
dict = {}
line = 1
for key in open(DICTIONARY, "rt").readlines():
dict[key.strip()] = line
line += 1
print "Creating perfect hash"
(G, V) = CreateMinimalPerfectHash( dict )
for word in TEST_WORDS:
line = PerfectHashLookup( G, V, word )
print "Word %s occurs on line %d" % (word, line)
Experimental Results
I prepared separate lists of randomly selected words to test whether the runtime is really linear as claimed.| Number of items | Time (s) |
|---|---|
| 100000 | 2.24 |
| 200000 | 4.48 |
| 300000 | 6.68 |
| 400000 | 9.27 |
| 500000 | 11.71 |
| 600000 | 13.81 |
| 700000 | 16.72 |
| 800000 | 18.78 |
| 900000 | 21.12 |
| 1000000 | 24.816 |
Here's a pretty chart.
CMPH
CMPH is an LGPL library that contains a really fast implementation of several perfect hash function algorithms. In addition, it compresses the G array so that it can still be used without decompressing it. It was created by the authors of one of the papers that I cited. Botelho's thesis is a great introduction to perfect hashing theory and algorithms.gperf
Gperf is another open source solution. However, it is designed to work with small sets of keys, not large dictionaries of millions of words. It expects you to embed the resulting tables directly in your C source files.Dr. Daoud's Page
Dr. Daoud contacted me below. Minimal Perfect Hashing Resources contains an even better implementation of the algorithm with a more compact representation. He originally invented the algorithm in 1987 and I am honoured that he adapted my python algorithm to make it even better!
Steve Hanov makes a living working on
Rhymebrain.com,
rapt.ink,
www.websequencediagrams.com,
and Zwibbler.com. He lives in
Waterloo, Canada.
Post comment
edit
jesboat
three years ago
Juliet asked:
> What does this mean? Minimal perfect hash functions would have been exactly what I need (looking up values associated with a static immutable collection of dozens of thousands of string keys in limited memory), except that I have to be able to detect when a key doesn’t belong in the collection. Is there no way to do this without storing the actual key strings somewhere? That would really be spatially inefficient…
>
> Come to think of it, how can regular hash maps in popular programming languages even detect false positives? False positives an intrinsic risk with any hash function, right? So do they always store a reference to a copy of the key itself?…
Unfortunately, to *guarantee* (strictly speaking) that the key was in the table, you do need to store a copy of the full key. This is what "standard" hashtables do; see e.g. HashMap.java (openjdk jdk8 source, line 280).
The only way I'm aware of to avoid that would be to use a cryptographic hash function. (You may have heard some cryptographic hash functions have been broken. Both MD5 and SHA1, which were commonly used, were broken, and it's specifically their collision-resistance which was broken, and collision-resistance is the property you need.) Using SHA256 would be safe, and the chance of a false positive due to a SHA256 collision would be smaller than the chance of a false positive due to a CPU error. Storing the SHA256 hashes of every key would be an additional 32 bytes per entry. You can truncate the SHA256 at the cost of increasing the probability of a false positive.
There are other datastructures which aim to detect membership in a set with small storage space which may be useful, e.g. Bloom filters. I don't remember the tradeoffs between space and chance of false positives off the top of my head.
edit
R
six years ago
There's a bug in Dr. Amjad M Daoud's python code,
if len(pattern) <= 1: break
This should be (because that pattern still needs hashing):
if len(pattern) <= 1:
b -= 1
break
edit
Chris Trenkamp
six years ago
I like this. Here's a Go example with some changes based on the comments:
github.com/ChrisTrenkamp/mph/
Some micro-benchmarks show it's a little slower than the Compress, Hash, Displace algorithm because this algorithm does two hashes: one for the intermediate key lookup and one for the actual key lookup. CHD makes one hash. This is the implementation I'm comparing it to.
github.com/robskie/chd/
Is it possible to tweak this algorithm so it only makes one hash? The FNV algorithm is simple and quick, but if it needs to be replaced, it could drastically affect the lookup times.
edit
Juliet
six years ago
> Esteban: To avoid false positives when retrieving a key, the (full) hashes must be stored in an array to check the key is valid. Just retrieve the stored hash as the values are (it's an extra value after all)
What does this mean? Minimal perfect hash functions would have been exactly what I need (looking up values associated with a static immutable collection of dozens of thousands of string keys in limited memory), except that I have to be able to detect when a key doesn’t belong in the collection. Is there no way to do this without storing the actual key strings somewhere? That would really be spatially inefficient…Come to think of it, how can regular hash maps in popular programming languages even detect false positives? False positives an intrinsic risk with any hash function, right? So do they always store a reference to a copy of the key itself?…
edit
Bruce
seven years ago
This is a really elegant algorithm! Thanks for implementing it in an easy to understand way. I couldn't decipher the paper myself, but your implementation cleared it up for me.
The paper also mentions compression schemes to reduce the number of bits required per key while maintaining O(1) lookup. Curious as to whether you've tried implementing any of those compression schemes?
edit
Guanyao
seven years ago
I try to code c++ version and I think there is one problem with this code. The following code might fail to find such d.
==================
while item < len(bucket):
slot = hash( d, bucket[item] ) % size
if values[slot] != None or slot in slots:
d += 1
item = 0
slots = []
else:
slots.append( slot )
item += 1
==================
Suppose d is bounded by 32 bits, it is possible that after we iterate all the d values we still fail to find a proper d.
The hash function is purely random. We don't know when it will actually ends. Maybe the expectation is linear with size, but in reality sometimes it never ends.
edit
Esteban
seven years ago
To avoid false positives when retrieving a key, the (full) hashes must be stored in an array to check the key is valid. Just retrieve the stored hash as the values are (it's an extra value after all)
edit
Jim Belton
eight years ago
Dr. Daoud's updated algorithm is not linear. He has a nested loop, making it O(n^2). While your code runs in 1.7s, when I run his code, it gets stuck in the nested loop. I gave up and hit Ctrl-C after more than 6 hours.
edit
Keith Beckman
ten years ago
In response to Anurag's comment, I've been implementing this in C to get a feel for MPHFs. While my tests haven't shown this particular degenerate case, I believe it can be generalized away from the LSB to simply what happens when all items in the initial set hash to the same initial bucket.
The solution seems to me detection of the specific degenerate case where all keys hash to the same bucket, and picking an alternate initial d value (which would have to be stored and transmitted as part of the hash function).
In fact, picking a random 32-bit value for the initial d as a matter of course, and always checking to ensure fewer than 50% of the keys are in any one bucket (to prevent protracted searches for the secondary d for that bucket) would probably be the most general way to handle both sets of degenerate cases (all keys hashing to a single initial bucket, and a single initial bucket being too full to allow efficient search for a valid secondary d value).
edit
Benjamin Schleimer
ten years ago
Wow, this is exactly what I needed for my project. It was super easy to adapt this to binary perfect hashing.
For anyone who is interested, the hash algo for binary data is:
def hash( d, key ):
if d == 0: d = 0x01000193
for num in key:
d = ( (d * 0x01000193) ^ num ) & 0xffffffff;
return d
It worked for tupls of binary data which was what I really needed. All of the mph implementations ONLY work with ascii text which is kinda annoying. Thanks for your awesome implementation!
Cheers
Ben
edit
Vijay
eleven years ago
Try generating MPH for the following sets:
1. ["hello", "world", "out", "there"]
2. ["hell", "not"]
I understand that the code is meant to be illustrative; just mentioning it in case someone is breaking their head right this minute :-)
edit
Anurag
eleven years ago
Hi Steve
There are cases when the program does not terminate. Here is a sample case:
dict = {"a": 1, "c": 2} # i.e., keys are "a" & "c"
----
Brief explanation of why the program get stuck:
----
The program is stuck forever inside the loop starting on line 56. The reason is: For a fixed "d", and len(str) == 1, the function hash(d, str) always returns a value whose last bit (LSB) depends only and only on the LSB of ord(str[0]). And in the loop (on line 56) we are doing this:
slot = hash( d, bucket[item] ) % size
In this case size == 2, so we are effectively only looking at the last bit of hash()'s output, which unfortunately will be same for both "a" (97), and "c" (99). The loop is constructed such that if same slot is returned for both keys, it will continue forever, and as we demonstrated above for same "d" slot will always be same for these two keys ("a", & "c").
Of course the argument shows that there is a family of inputs which will make the program go on forever (e.g., of len(dict) == 2 cases: {"a", "c"}, {"a", "e"}, .... and so on). Similar examples can be constructed for even len(dict) > 1 cases.
Do you have any suggestions on how to fix the problem ?
Thanks
Anurag
PS: Just for my own reference, edit password for the post: SHA-256(level 2 trivial password).
edit
Steve Hanov
eleven years ago
Hi Ryan,
This data structure will always find an entry even if you use a key that is not in it. It assumes that you only look up things that you know are stored in it. Use it only when you have some other means of finding out whether an item is valid..
edit
Matt
eleven years ago
(Edited) I had something here about the code getting into an infinite loop, but it was because I was testing with randomized keys and not not thinking about non-unqiue keys like a dummy.
edit
Ryan
eleven years ago
Stumbled onto this post, and tested some code:
for fake in ["fgouijnbbtasd", "hlubfanbybjhfbdsa", "oun987qwve76cvwa"]:
line = PerfectHashLookup(G,V,fake)
print "Word %s occurs on line %d" % (fake, line)
and then get:
Word fgouijnbbtasd occurs on line 88236
Word hlubfanbybjhfbdsa occurs on line 60409
Word oun987qwve76cvwa occurs on line 75101
Not sure if this is the expected behavior:
$ cat /usr/share/dict/words | awk 'NR == 88236 || NR == 60409 || NR == 75101'
masseurs
reactivation
supplanted
edit
Amjad M Daoud
twelve years ago
This is an algorithm i developed in my thesis ... described as algorithm II in the following paper:
"Edward A. Fox, Lenwood S. Heath, Qi Fan Chen and Amjad M. Daoud, Practical minimal perfect hash functions for large databases, CACM, 35(1):105-121"
edit
Gregory LEOCADIE
twelve years ago
Hello,
have some stats about the memory used by your data structures for your different sets of keys ?
edit
Chad
13 years ago
I enjoy your simplifications; sketched pictures just make everything easy to understand.
Your code would need O(n log n) bits to store the intermediate table, G (n entries, log base 2 of n bits to represent the index). There are other algorithms that store a constant number of bits per entry via compressing their intermediate table using a Huffman like encoding while still maintaining O(1) access time.
edit
Rakesh
13 years ago
Steve, Thx for this article. in Bothelo's thesis the information theoretic lower bound of number of bits to describe a PMH is derived as the reciprocal of the probability that a random function from S (of size n) to the set {0,1,2..,m} is a perfect hash. Any idea how this follows? (I could in theory see the references cited there but was wondering if it is something you know off hand.)
edit
Alex
14 years ago
Hi Steve! Your blog very nice! I like it, can you help me a problem? Alrorithm MA-FSA or DAWG. Have you set by java? you for me! oK?
my mail: dungtp_53@vnu.edu.vn or phidungit@yahoo.com
coming soon!