
A Quick Measure of Sortedness
The Kendall distance between two lists is the number of swaps it would take to turn one list into another. So, for [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] and [10, 1, 2, 3, 4, 5, 6, 7, 8, 9], it would take nine swaps.
Edit distance is another method. We could take the 10, and move it after the 9, in one operation. The edit distance is inversely related to the longest increasing subsequence. In the list [1, 2, 3, 5, 4, 6, 7, 9, 8], the longest increasing subsequence is [1, 2, 3, 5, 6, 7, 9], of length seven, and it is three away from being a sorted list. The longest increasing subsequence can be calculated in O(nlogn) time. A drawback of this method is its large granularity. For a list of ten elements, the measure can only take the distinct values 0 through 9.
Here, I propose another measure for sortedness. The procedure is to sum the difference between the position of each element in the sorted list, x, and where it ends up in the unsorted list, f(x). We divide by the square of the length of the list and multiply by two, because this gives us a nice number between 0 and 1. Subtracting from 1 makes it range from 0, for completely unsorted, to 1, for completely sorted.
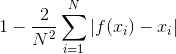
A simple genetic algorithm in python for sorting a list using the above fitness function is presented below.
import random
def procreate(A):
A = A[:]
first = random.randint(0, len(A) - 1)
second = random.randint(0, len(A) - 1)
A[first], A[second] = A[second], A[first]
return A
def score(A):
diff = 0.
for index, element in enumerate(A):
diff += abs(index - element)
return 1.0 - diff / len(A) ** 2 * 2
def genetic(root, procreateFn, scoreFn, generations = 1000, children=6):
maxScore = 0.
for i in range(generations):
print("Generation {0}: {1} {2}".format(i, maxScore, root))
maxChild = None
for j in range(children):
child = procreate(root)
score = scoreFn(child)
print(" child score {0:.2f}: {1}".format(score, child))
if maxScore < score:
maxChild = child
maxScore = score
if maxChild:
root = maxChild
return root
A = [a for a in range(10)]
random.shuffle(A)
genetic(A, procreate, score)
Note that under this metric, the completely reversed list does not have a score of 0.
The Spearman's coefficient, mentioned in the comments, might be what you are looking for.
Comments